Over the final few weeks of the last trimester, for one of my modules I have been doing research into different methods of parallelism, how effective they are on performance and generally whether or not I can get much of a speed up with them. This post will discuss the algorithm used, optimisations performed and the specific results into this test. Overall it was found that combining multiple different paralellisation together (MPI & C++ threads & SIMD) produced the fastest speed up although this was not nearly as fast as the GPU compute shader version that was tested.
If you like percentages and data this is the post for you. I will make a post later and link to relevent articles on how I went about optimising these different versions another day.
Algorithm
The algorithm I tested was a simple N-body with gravity. The serial version that was used as a baseline and tested against the other versions of the applications was based on the version taken from the DirectX SDK and as such uses certain DirectX data structures although these are unnecessary. The algorithm is as follows.
// Body to body interaction, acceleration of the particle at
// position bi is updated
void bodyBodyInteraction(D3DXVECTOR3& ai, D3DXVECTOR4& bj, D3DXVECTOR4& bi,
float mass, int particles )
{
// Get the vector between the two points
D3DXVECTOR3 r = D3DXVECTOR3(bj.x - bi.x, bj.y - bi.y, bj.z - bi.z);
float distSqr = dot(r, r); // Find the dot product of the vector
distSqr += softeningSquared;
float invDist = 1.0f / sqrt(distSqr);
float invDistCube = invDist * invDist * invDist;
float s = mass * invDistCube * particles;
// Update the acceleration with the calculated value
ai = D3DXVECTOR3(ai.x + (r.x * s), ai.y + (r.y * s), ai.z + (r.z * s));
}
// Call this function to calculate the next position of all the bodies
// in the system, represents a single pass
void calculateGravity()
{
// Loop through every particle in the system
for(int i = 0; i < MAX_PARTICLES; i++)
{
D3DXVECTOR4 pos = pData1[i].pos; // Stash a local copy of
D3DXVECTOR4 vel = pData1[i].velo; // the position and velocity
D3DXVECTOR3 accel = D3DXVECTOR3(0, 0, 0);
float mass = g_fParticleMass;
// Calculate acceleration to be applied to the
// using all the other particles in the system
for (int tile = 0; tile < MAX_PARTICLES; tile++)
bodyBodyInteraction(accel, pData1[tile].pos, pos, mass, 1);
// Update the velocity and position of current particle using the
// acceleration computed above
vel = D3DXVECTOR4( vel.x + accel.x * 0.1f,
vel.y + accel.y * 0.1f,
vel.z + accel.z * 0.1f,
vel.w);
vel *= 1; // damping
pos += vel * 0.1f; // apply deltaTime
pData2[i].pos = pos; // Save the newly calculated position and velocity
pData2[i].velo = D3DXVECTOR4(vel.x, vel.y, vel.z, length(accel));
}
pData1 = pData2; // Swap the buffers
}
The above algorithm represents that simple sequential version used for the tests, the data structures can be changed for arrays of floats, vectors or anything else but the underlying theory is the same. For each particle in the system, calculate the gravitational effect on it based upon every other body in the system. The bodyBodyInteraction function above calculates the acceleration effect upon one body based upon another, whilst the actual acceleration is applied after this has been calculated in the calculateGravity function. It is then applied and stored in pData2 which is a temporary list of all the new positions so that later particles in the list can still refer to the old positions. After all the calculations are complete we can then switch pData1 and pData2 and then loop the process ad infinitum.
Optimisations
I optimised this algorithm for multiple versions using C++11 threads, MPI and SIMD with a comparison against a version with DirectCompute shaders found in the DirectX SDK. Since this problem is primarily a data parallel problem I simply modified the algorithm slightly so that I could split up the data set to work across multiple cores or machines. SIMD required much more modification of data structures and instructions to properly function. The change can be seen below.
void calculateGravity(int start, int end)
{
for(int i = start; i < end; i++)
{
The algorithm will now work by specifying a range of values to work upon in the range of data. This is useful for the multi-threaded approach where thread 0 will do the first group of values, 0 - 255 for example, then thread 1 will do the second group, 256 - 511. This follows the parallel data and sequential processing model.
SIMD
SIMD (Single Instruction Multiple Data) by far required the biggest changes through the code, the main things that were changed were the use of the D3DX11VECTOR types which were changed to 32 byte __m128 values instead. Luckily the position and velocity information for each particle fit perfectly into these types as they are also represented by 4 floats each. The other primary change was the use of SIMD operations. Since there were a large number of changes made more details on these changes will be outlined in another post.
// Body to body interaction, acceleration of the particle at position bi is updated
void bodyBodyInteraction(__m128& ai, __m128& bj, __m128& bi, float mass, int particles )
{
__declspec(align(16)) __m128 r = _mm_sub_ps(bj, bi);
float distSqr = dot(r, r);
distSqr += softeningSquared;
float invDist = 1.0f / sqrt(distSqr);
float invDistCube = invDist * invDist * invDist;
auto s = _mm_set1_ps( mass * invDistCube * particles );
ai = _mm_add_ps(ai, _mm_mul_ps(r, s));
}
In the above code the distance between bodies is defined as __declspec(align(16)) __m128 this means that we are using a memory alignment of 16 bits on our __m128 data type. This data type is used for the Streaming SIMD Extension (SSE) instructions.
The first instruction used in this section is _mm_sub_ps(bj, bi), this simply subtracts the values of bi from bj. With these SSE instructions we can perform the subtraction of each part at the same time on the CPU instead of one after the other. This should give us a theoretical speed up of four times for this single calculation.
The other instructions used in this section were _mm_add_ps which adds two __m128 together, _mm_mul_ps which multiplies two __m128s and _mm_set1_ps which simply sets all the values in an __m128 to the value defined.
By altering all of these vector operations to use SIMD we can make use of the hardware support on the CPU to speed up the time taken for a single operation. Whilst the speed gain for a single operation may be relatively negligible, we are doing them multiple thousands of times resulting in a compounding speed saving. It was interesting to note that despite both Intel and AMD supporting SSE instructions only the Intel CPU received a speed increase, the application ended up running slower on AMD hardware. This highlights some of the difficulties of using SIMD as you must take in account specifics of the CPU you are programming for. Memory alignment and how the individual CPU processes the instructions can result in differing level of speed increases. Improving the speed on the AMD machine was beyond the scope of this project but I have no doubt that it is possible.
C++11 Threads
For the C++11 threads we create the threads as follows.
// split up work for number of threads in system
for(int j = 0; j < num_threads; ++j)
{
threads.push_back(thread([=](){ calculateGravity(start, end); }));
}
for(auto& t : threads)
t.join();
pData1 = pData2; // Since it's multi-threaded we do the
// buffer switch after all threads are complete
}
The main changes are that now we must switch the data buffers after all threads have been rejoined as opposed to inside the function due to the parallel approach we have taken. The C++ threaded application simply splits up the data amongst each of the availible hardware threads for processing then rejoins at the end. As such the amount of speed increase is dependent upon the number of hardware threads available.
Since this application makes use of the number of cores on the CPU, this could be combined with the SIMD level parallelism and as such a version of this application was also produced taking into account the changes made by the SIMD application. It was found that this version did offer a speed up over the threaded or SIMD version alone.
I’ll write a more detailed post about C++11 threading and how to do so and put a link here when it is done.
MPI
MPI (message passing interface) allows distributed applications to communicate across networks to each other. The main communication methods that were used for this application were MPI_BROADCAST and MPI_SENDRECV these two processes allowed the application to communicate the data across all machines and then have each machine send it back to a host machine.
Using MPI, multiple instances of the application can be running across different computers in a network, each one has an ID, with the host as 0. As such for these applications, all of the data was sent out to each machine on the network. Each machine that is not the host machine will wait until it has received its data before it goes on to process it, the host machine will then start sending the data to all the machines depending on the communication method being used. MPI_BROADCAST sends the data specified to all machines in the network and requires all of the nodes to be listening and call it at the same time. The other method is MPI_SENDRECV which acts as a point to point communication between two nodes. For the version of the application created I instead used MPI_SEND and MPI_RECV the distinction being that these are uni-directional. One process on the system will call MPI_SEND and the specified node must then at some point call MPI_RECV, if either node is not ready to send or receive then that node will wait. This was used for the communication of the newly calculated positions back to the main node.
The code below shows the point that decides which part of the application is run by the node itself. my_rank is the nodes rank within the communication network, a rank of 0 belongs to the host node. As such, if you are not rank 0 then you are worker node, in this manner the stuff within the first if statement is performed only by the worker nodes.
if (my_rank != 0)
{
// Not main process - wait to receive message
PARTICLE* message = new PARTICLE [ MAX_PARTICLES ];
// Wait to receive data from host node
MPI_Bcast(message, MAX_PARTICLES * 8, MPI_FLOAT, 0, MPI_COMM_WORLD);
pData1 = message;
calculateGravity(0 + (divide * my_rank), divide + (divide * my_rank));
pData1 = pData2;
message = new PARTICLE [divide];
for(int k = 0; k < divide; ++k)
message[k] = pData1[k + (divide * my_rank)];
MPI_Send(message, divide * 8, MPI_FLOAT, 0, 0, MPI_COMM_WORLD);
}
The below else statement is what is performed by the host node. The primary differences are that it needs to initialize the particle system, broadcast the data out to all the nodes, calculate a portion of the data and the finally rejoin all of the calculated data from across the network.
else
{
InitiliaseParticles();// Initilise the groups of particles
// Send out the list of particles to all nodes
MPI_Bcast(pData1, MAX_PARTICLES * 8, MPI_FLOAT, 0, MPI_COMM_WORLD);
calculateGravity(0 + (divide * my_rank), divide + (divide * my_rank));
pData1 = pData2;
for(int k = 1; k < num_processes; ++k)
{
PARTICLE* message = new PARTICLE [ divide ];
MPI_Recv(message, divide * 8, MPI_FLOAT, k, 0,
MPI_COMM_WORLD, MPI_STATUSES_IGNORE);
for(int x = 0; x < divide; ++x)
pData1[x + (divide*k)] = message[x];
}
}
The MPI version of the application was combined and tested with all other versions of the application. Since MPI is just a method of communicating between computers this meant that each computer itself could still benefit from the other parallelisation techniques to make use of the local hardware. Of course, in this instance the biggest performance factor was the speed of the network.
It was interesting to note that the application seriously slowed down for the smallest of data sizes, this was due to the transfer time of the data being higher than the time taken to process it on a single machine. As such it is important to take this into consideration when designing your application.
More details into MPI and their functions will be outlined in a post in future.
Test Results
The main applications that were tested were as follows:
- Sequential N-Body
- Sequential N-Body – With SIMD
- Parallel N-Body – C++11 Threads to split up data
- Parallel N-Body - C++11 Threads (with SIMD)
- Parallel N-Body – Compute Shader (GPU SIMD )
- Parallel N-Body – MPI with Multiple computers (Sequential)
- Parallel N-Body – MPI with Multiple computers (Parallel)
The applications were tested on two different systems, one Intel based and the other AMD.
| CPU Name | Year | CPU Speed | Cores | GPU | NM | Cache | |
|---|---|---|---|---|---|---|---|
| Computer 1 - Home | AMD Phenom II X6 1055T | 2010 | 3.25 GHz | 6 | GTX 460 | 336 CUDA Cores | 1 GB GDDR5 @ 1800 MHz |
| Computer 2 - University | Intel i5 2500 | 2011 | 3.3 GHz | 4 | GTX 550 Ti | 192 CUDA Cores | 1 GB GDDR5 @ 1,026 MHz |
The cluster used for each of the MPI tests were combinations of 2, 4, 8 and 16 computers all with the same configuration as Computer 2 in the above table connected over a 100 Mbit network.
Sequential
The baseline speeds for each computer running the sequential version of the application was as follow:
| Serial | 1024 | 2048 | 4096 | 8192 | 16,384 | 32,768 | 65536 |
|---|---|---|---|---|---|---|---|
| Computer 1 (ms) | 78 | 328 | 1359 | 5484 | 22013 | 88429 | 357092 |
| Computer 2 (ms | 67.75 | 250 | 992.7 | 3961 | 15839 | 63843 | 254323 |
As can be seen in the above results the differences between Computer 1 & 2 are minor and there is no difference between the two as the data size increases. The times from this algorithm will form the base case to compare against the other optimisations later on. It is interesting to note that Computer 1, despite having 6 cores, has no performance increase over Computer 2, this shows clearly that there is much room to make use of the parallel hardware available in the system.
For the following results, speed up shows how the speed of the parallel application ran compared with the sequential version. A speed up of 100% in this case
Sequential with SIMD
The first optimisation that was tested was the SIMD version of the application. The test results and speed up versus the baseline version are shown below.
| SIMD | 1024 | 2048 | 4096 | 8192 | 16,384 | 32,768 | 65536 |
|---|---|---|---|---|---|---|---|
| C1 | 78 | 328 | 1359 | 5484 | 22013 | 88429 | 357092 |
| C1 (w/ SIMD) | 93 | 375 | 1527 | 6077.75 | 23982 | 96716 | 387619 |
| Speed Up | -16% | -13% | -11% | -10% | -8% | -10% | -9% |
| C2 | 67.75 | 250 | 992.75 | 3961.5 | 15839 | 63843.5 | 254323 |
| C2 (w/ SIMD) | 43.25 | 168.75 | 676.25 | 2694.5 | 10655 | 42562.5 | 170354 |
| Speed Up | 57% | 48% | 47% | 47% | 49% | 50% | 49% |
As we can see from the above results, on the AMD based Computer 1 there was actually a reduction in performance when using these specific SIMD instructions. Computer 2 on the other hand received a moderate speed boost. Since SIMD in this case is performing 4 operations at the same time it is expected that the maximumm possible speed boost would be 4 times faster. This shows that more work is needed to realise the full potential of SIMD on the CPU for this application.
C++ Threads
These are the results for the application that used just threads by themselves.
| C++ Threads | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|
| C1 | 78 | 328 | 1359 | 5484 | 22013 | 88429 | 357092 |
| C1 (C++ Threads) | 15 | 62 | 265 | 953 | 3734 | 14968 | 59709 |
| Speed Up | 420% | 429% | 412% | 475% | 489% | 490% | 498% |
| C2 | 67.75 | 250 | 992.75 | 3961.5 | 15839 | 63843.5 | 254323 |
| C2 (C++ Threads) | 19 | 80.75 | 278.75 | 1100.75 | 4411.75 | 17523 | 70323.8 |
| Speed Up | 257% | 209% | 256% | 259% | 259% | 264% | 261% |
As we can see above, the AMD based CPU, Computer 1, received the biggest speed improvement and managed to surpass the Intel CPU which only had 4 cores. Both CPUs managed to achieve a much higher speed improvement much closer in line with the level of parallelism supported by each CPU. Computer 1 achieves nearly its ideal speed improvement of 6 times whilst computer achieves nearly 4 times.
C++ Threads (with SIMD)
These results relate to the threaded version that was also combined with SIMD to see if much more of a signifcant speed increase could be obtained. In the interests of keeping this article shorter the specific timing values have been omitted and can be found in the appendix.
| C++ Threads (with SIMD) | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|
| Computer 1 | |||||||
| ThreadsSpeed Up | 420% | 429% | 412% | 475% | 489% | 490% | 498% |
| Threads & SIMDSpeed Up | 222% | 393% | 415% | 433% | 427% | 423% | 416% |
| Computer 2 | |||||||
| ThreadsSpeed Up | 257% | 209% | 256% | 259% | 259% | 264% | 261% |
| Threads & SIMDSpeed Up | 344% | 441% | 397% | 372% | 359% | 364% | 362% |
MPI
There was a lot of data in the MPI test results and as such these have been omitted. I will post a link to the full report when it is completed so that exact figures can be seen. In the mean time I have plotted a graph below with speed differences. The main point to note for the MPI results was that for the small data sizes it resulted in significant slow down, the more computers thrown at the problem the slower it got. Only at the larger data sizes was a performance increase shown but it shows that MPI would be more effective than the other techniques at the largest of data sizes.
Final Comparisons
There is a lot more data in relation to the rest of the results but they can be found in the actual report.
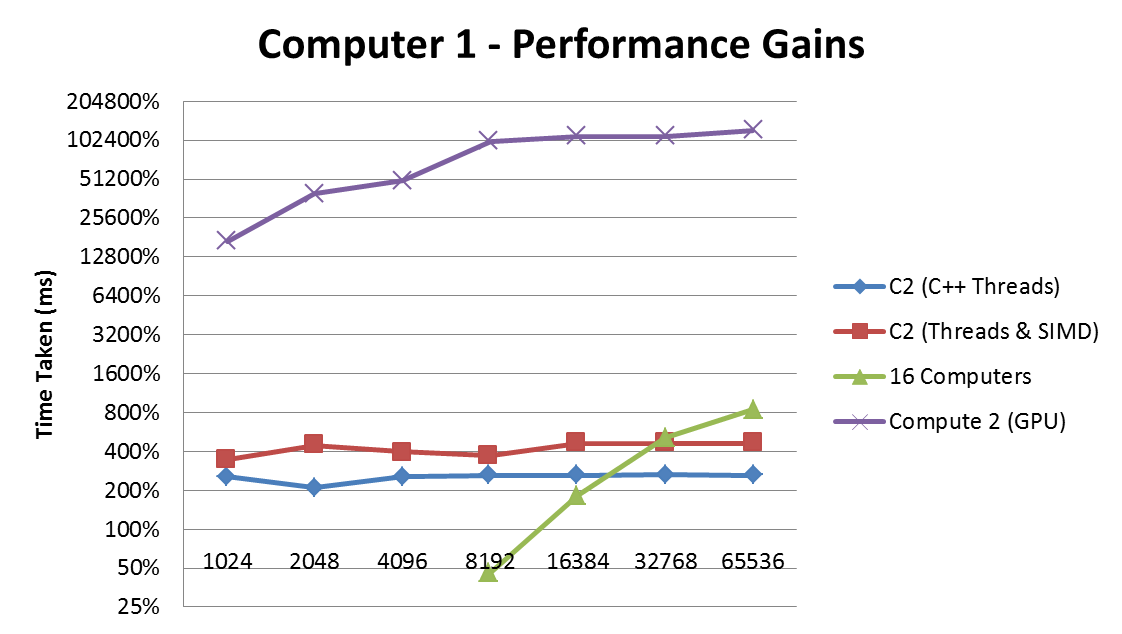
The table below shows the percentage speed up of each different application over the varying data sets (Although useful, the information relating to the AMD system has not been plotted). Here we can see that the fastest version was indeed the GPU version which was several thousand times faster than the sequential version. Even in comparison to the other techniques it is a mile ahead. Despite this, C++ threads and SIMD manage to make a consistent speed up over all of the data sets. The major point of interest in this example is that the MPI version of the application actually performs significantly worse at smaller data sizes than all of the other applications. It does manage to make a speed up at the highest of data sizes and based on this trend I predict it could gain an even better speed up at larger data sizes.
I wrote this in a bit of a rush so if there are any inaccuracies or inconsistencies or if you simply have a question feel drop me a message and I’ll fix them up or get back to you ASAP.